Since HBase-4336 (and HBase 0.96) the HBase source code has been split into multiple maven modules.
The post is no more related to a specific operating system, you can follow these steps on Linux or Windows.
$ svn checkout http://svn.apache.org/repos/asf/hbase/trunk hbase
(check http://hbase.apache.org/source-repository.html for more details)


Some java sources need to be generated, right click on the hbase project, Run As and select "Maven generate-sources" :


In the Arguments tab add the program arguments start :

Give it a try, click on the Run button :

You can also try the HBase web interface http://localhost:60010 :



The post is no more related to a specific operating system, you can follow these steps on Linux or Windows.
0. Requirements
- Java :)
- Eclipse (Eclipse IDE for Java Developers should be ok)
- A Subversion client (since i'm under Microsoft Windows i use the Collabnet one, with Linux use you favorite package tool e.g. : apt-get install subversion)
1. Checkout sources
Use your favorite Subversion client to checkout the HBase source code :$ svn checkout http://svn.apache.org/repos/asf/hbase/trunk hbase
(check http://hbase.apache.org/source-repository.html for more details)

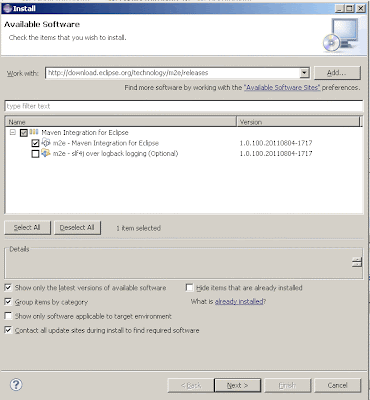
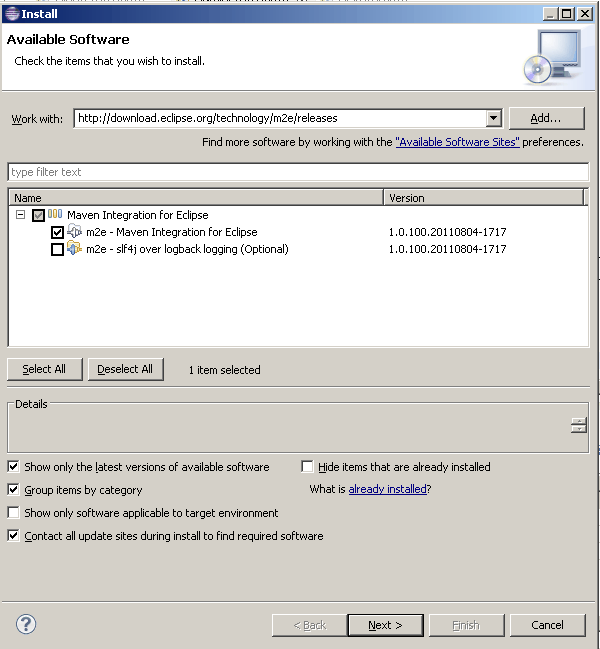
2. Install M2Eclipse plugin
- Select the menu : Help / "Install New Software"
- In the 'Work with' field type : http://download.eclipse.org/technology/m2e/releases (press Enter)
- Select m2e - Maven Integration for Eclipse
3. Import HBase source code
File - Import... - Maven / Existing Maven Projects and select the directory where sources have been checked out at step 1 :
Some java sources need to be generated, right click on the hbase project, Run As and select "Maven generate-sources" :

4. Create Run configuration
Create a new run configuration, name it 'HBase (start)', slect the hbase-server project and set org.apache.hadoop.hbase.master.HMaster as the main class :

Give it a try, click on the Run button :

You can also try the HBase web interface http://localhost:60010 :

5. Create HBase Shell Run configuration
Create a new Run configuration, set the Name to Shell, and select org.jruby.Main as the main class :

In the Arguments tab :
- Add the path to the bin/hirb.rb file as the program argument
- Set the Java variable hbase.ruby.sources to the path src/main/ruby path (e.g. -Dhbase.ruby.sources=D:\HBASE\hbase-trunk\hbase-server\src\main\ruby)

Comments
Post a Comment